


关注矿山人工智能 查看前沿咨询
企业使命
引领行业科技未来,贡献战略核心技术,满足市场科技需求,支撑集团创新发展。
企业愿景
建成集聚顶尖人才、勇攀第一高峰、激扬第一动力的世界能源科技研究中心。
概述
《Janus-Pro: Unified Multimodal Understanding and Generation with Data and Model Scaling》是由DeepSeek-AI团队于2025年发表的多模态模型研究,旨在通过统一框架实现多模态理解(如图像描述、文档解析)与生成(如文本到图像合成)的协同优化。作为Janus模型的升级版,Janus-Pro通过训练策略优化、数据扩展和模型规模化三大改进,显著提升了性能,并在多个基准测试中超越LLaVA、DALL-E 3等模型。其代码与模型已开源,支持7B参数规模,具备较强的工业应用潜力。


引言
近期,在统一多模态理解和生成模型方面已经取得了显著的成果。这些方法已被证明能够增强视觉生成任务中的指令遵循能力,同时减少模型的冗余性。然而,这些方法大多使用相同的视觉编码器来处理多模态理解和生成任务的输入,由于两种任务所需的表征不同,常常导致在多模态理解任务上表现欠佳。为了解决这一问题,Janus提出了视觉编码解耦的方案,从而缓解了多模态理解和生成任务之间的冲突,实现了在两项任务中的卓越表现。
作为一款开创性的模型,Janus在10亿参数规模上得到了验证。然而,由于训练数据量有限且模型容量相对较小,它在某些方面表现出了不足,例如在短提示图像生成方面表现欠佳,以及文本到图像生成质量不稳定。在本文中,我们介绍了Janus-Pro,这是Janus的一个增强版本,它在三个维度上进行了改进:训练策略、数据和模型规模。Janus-Pro系列包括两个模型规模:10亿和70亿,这证明了视觉编码解码方法的可扩展性。
在多个基准测试中对Janus-Pro进行的评估结果表明其在多模态理解方面表现出色,并且在文本到图像指令遵循方面有了显著提升。具体来说,Janus-Pro-7B在多模态理解基准MMBench测试中获得了79.2分,超过了其他最先进的统一多模态模型,例如Janus(69.4分)、TokenFlow(68.9分)和MetaMorph(75.2分)。此外,在文本到图像指令遵循排行榜GenEval中,Janus-Pro-7B的得分达到了0.80,超过了Janus(0.61分)、DALL-E 3(0.67分)和Stable Diffusion 3 Medium(0.74分)。
图1展示Janus-Pro在多模态理解和视觉生成方面的定量结果。对于多模态理解,计算了POPE、MME-Perception、GQA和MMMU的平均准确率。MME-Perception的分数除以20以缩放到[0, 100]区间。对于视觉生成,在两个指令遵循基准GenEval和DPG-Bench上评估了性能。总体而言,Janus-Pro超越了以往的统一多模态模型以及一些特定任务的模型。
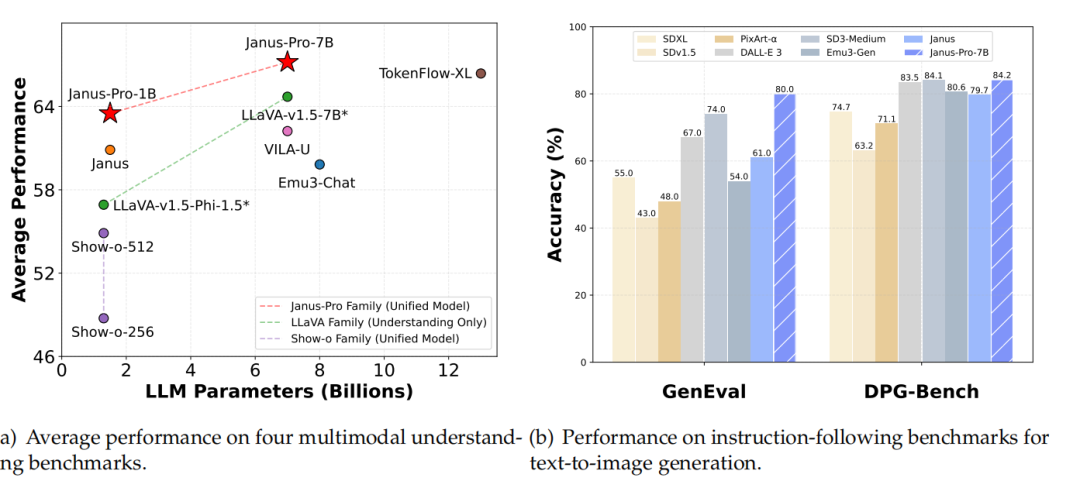
图 1 Janus-Pro在多模态理解和视觉生成方面的定量结果
图2展示了Janus-Pro与Janus在文本到图像生成方面的定量比较。Janus-Pro在处理简短提示时,能够提供更稳定的输出,生成的图像在视觉质量上有所提升,细节更加丰富,并且能够生成简单的文本内容。图像分辨率为384×384。

图 2 Janus-Pro与Janus在文本到图像生成方面的可视化结果
方法论
Janus-Pro的架构如图3所示,与Janus相同,为多模态理解和视觉生成解耦了视觉编码,其中“Und. Encoder”和“Gen. Encoder”分别是“Understanding Encoder”(理解编码器)和“Generation Encoder”(生成编码器)的缩写。
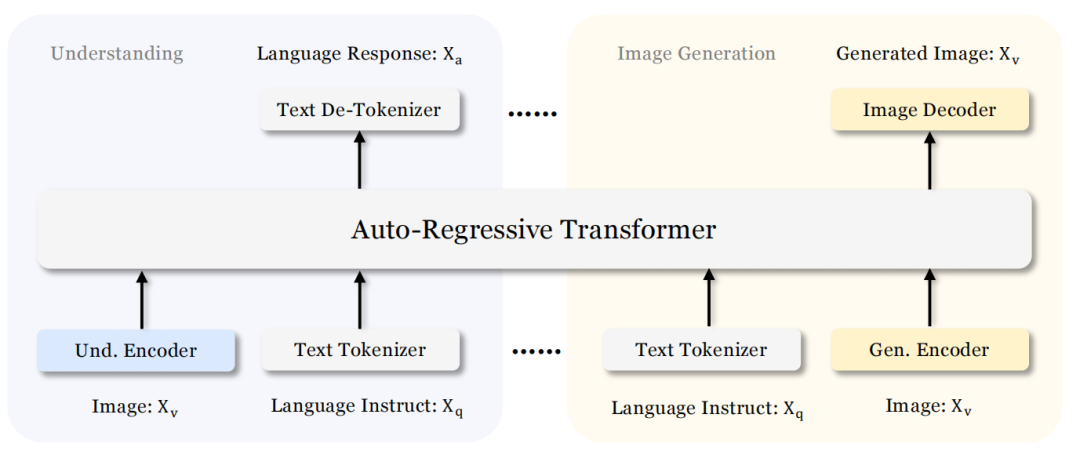
图 3 Janus-Pro架构
Janus-Pro整体架构的核心设计理念是将多模态理解和生成任务的视觉编码进行解耦。首先应用独立的编码方法将原始输入转换为特征,然后通过一个统一的自回归Transformer进行处理。对于多模态理解任务,使用SigLIP编码器从图像中提取高维语义特征。这些特征从二维网格展平为一维序列,并通过一个理解适配器(Understanding Adaptor)将图像特征映射到LLM的输入空间。对于视觉生成任务,使用文献LlamaGen的VQ tokenizer将图像转换为离散的ID序列。在将ID序列展平为一维后,使用一个生成适配器(Generation Adaptor)将每个ID对应的码本嵌入(Codebook Embeddings)映射到LLM的输入空间。随后,将这些特征序列拼接成一个多模态特征序列,并将其输入到LLM中进行处理。除了LLM内置的预测头外,Janus-Pro还为视觉生成任务中的图像预测使用了一个随机初始化的预测头。整个模型遵循自回归框架。
Janus-Pro的核心方法论围绕三个主要改进展开:优化的训练策略、扩展的训练数据以及更大的模型规模。这些改进使得Janus-Pro在多模态理解和文本到图像生成任务中表现出色。
1
优化的训练策略
Janus的早期版本采用了一个三阶段的训练流程。第一阶段专注于训练适配器和图像头部。第二阶段负责统一预训练,在此过程中,除了理解编码器和生成编码器外,所有组件的参数都会更新。第三阶段是监督微调,它在第二阶段的基础上进一步解锁理解编码器的参数以进行训练。这种训练策略存在一些问题。在第二阶段,Janus遵循PixArt的方法,将文本到图像能力的训练分为两部分。第一部分使用ImageNet数据进行训练,以图像类别名称作为文本到图像生成的提示,目的是建模像素依赖关系。第二部分则使用普通的文本到图像数据进行训练。在实际操作中,第二阶段中66.67%的文本到图像训练步骤被分配给了第一部分。然而,通过进一步的实验,Janus-Pro的作者们发现这种策略是次优的,并且会导致显著的计算效率低下。
为了解决这一问题,他们进行了两项改进:
延长第一阶段的训练时间:增加第一阶段的训练步骤,以便在ImageNet数据集上进行充分的训练。研究发现,即使在固定LLM参数的情况下,模型也能够有效地建模像素依赖关系,并根据类别名称生成合理的图像。
第二阶段的针对性训练:在第二阶段,放弃ImageNet数据,直接使用普通的文本到图像数据来训练模型,使其能够基于详细的描述生成图像。这种重新设计的方法使第二阶段能够更高效地利用文本到图像数据,从而提高了训练效率和整体性能。
此外,还在第三阶段的监督微调过程中调整了不同类型数据集的比例,将多模态数据、纯文本数据和文本到图像数据的比例从7:3:10调整为10:2:8。通过略微减少文本到图像数据的比例,使模型能够在保持强大的视觉生成能力的同时,实现更好的多模态理解性能。
2
扩展的训练数据
扩大了用于Janus的训练数据规模,涵盖了多模态理解和视觉生成两个方面。
多模态理解
在第二阶段的预训练数据中,参考了DeepSeek-VL2,增加了约9000万个样本。这些样本包括图像字幕数据集(例如YFCC),以及用于表格、图表和文档理解的数据(例如Docmatix)。在第三阶段的监督微调数据中,还引入了DeepSeek-VL2中的其他数据集,如表情包理解、中文对话数据以及旨在提升对话体验的数据集。这些新增内容显著扩展了模型的能力,丰富了其处理多样化任务的能力,同时提升了整体的对话体验。
视觉生成
Janus早期版本中使用的现实世界数据质量不足且存在大量噪声,这常常导致文本到图像生成的不稳定性,从而产生质量欠佳的输出。在Janus-Pro中,引入了约7200万个合成美学数据样本,在统一预训练阶段将真实数据与合成数据的比例调整为1:1。这些合成数据样本的提示词是公开可用的,例如在Midjourney prompts数据库中可以找到。实验表明,模型在合成数据上训练时收敛速度更快,生成的文本到图像输出不仅更加稳定,而且在美学质量上也有显著提升。
3
更大的模型规模
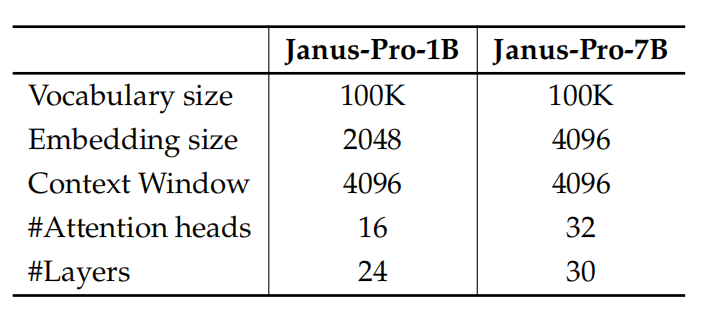
Janus的早期版本通过使用一个15亿参数的语言模型验证了解耦视觉编码的有效性。在Janus-Pro中,将模型规模扩展到了70亿参数。15亿参数和70亿参数的语言模型的超参数细节如表1所示。当使用更大规模的语言模型时,多模态理解和视觉生成任务的损失函数收敛速度显著快于较小规模的模型。这一发现进一步验证了这种方法的强大可扩展性。
表 1 Janus-Pro 架构的配置
实验
1
实验细节
在实验中,使用了DeepSeek-LLM(15亿参数和70亿参数)作为基础语言模型,其支持的最大序列长度为4096。对于理解任务中使用的视觉编码器,选择SigLIP-Large-Patch16-384。生成编码器有一个大小为16384的码本,并将图像下采样16倍。理解适配器和生成适配器均为两层的多层感知器(MLP)。表2展示了每个阶段的具体超参数配置,其中数据比例是指多模态理解数据、纯文本数据以及视觉生成数据之间的比例。
表 2 Janus-Pro 的具体超参数配置
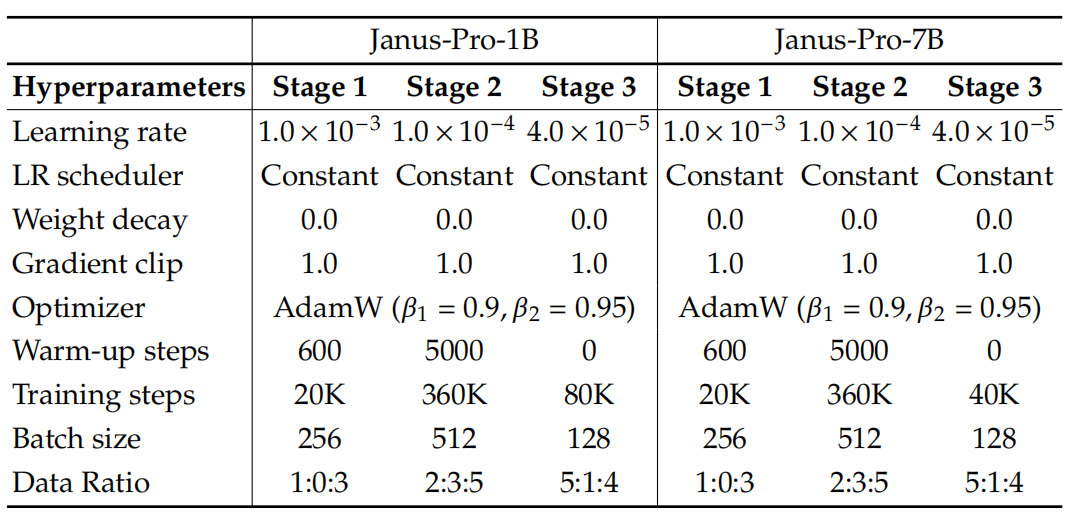
注意,在第二阶段,采用了提前停止策略,在训练到27万步时停止。所有图像都被调整为384×384像素的大小。对于多模态理解数据,调整图像的长边尺寸,并使用背景颜色(RGB值:127, 127, 127)填充短边,使其达到384像素。对于视觉生成数据,将短边调整为384像素,长边裁剪为384像素。在训练过程中,使用序列打包的方式来提高训练效率。在单个训练步骤中,按照指定的比例混合所有数据类型。
使用HAI-LLM训练和评估Janus-Pro,其中HAI-LLM是一个构建在PyTorch之上的轻量级且高效的分布式训练框架。对于15亿参数和70亿参数的模型,整个训练过程分别在由16和32个节点组成的集群上,分别耗时约9和14天,每个节点配备8块英伟达A100(40GB)GPU。
2
评估指标
多模态理解:为了评估多模态理解能力,在广泛认可的基于图像的视觉语言基准测试上对Janus-Pro进行评估,这些基准测试包括GQA、POPE、MME、SEED、MMB、MM-Vet和MMMU。
视觉生成:为了评估视觉生成能力,使用了GenEval和DPG-Bench。GenEval是一个具有挑战性的文本到图像生成基准测试,旨在通过对视觉生成模型的组合能力进行详细的实例级分析,来反映这些模型的综合生成能力。DPG-Bench(密集提示图基准测试)是一个综合性的数据集,由1065条冗长且密集的提示组成,旨在评估文本到图像模型复杂的语义对齐能力。
3
与最新技术的比较
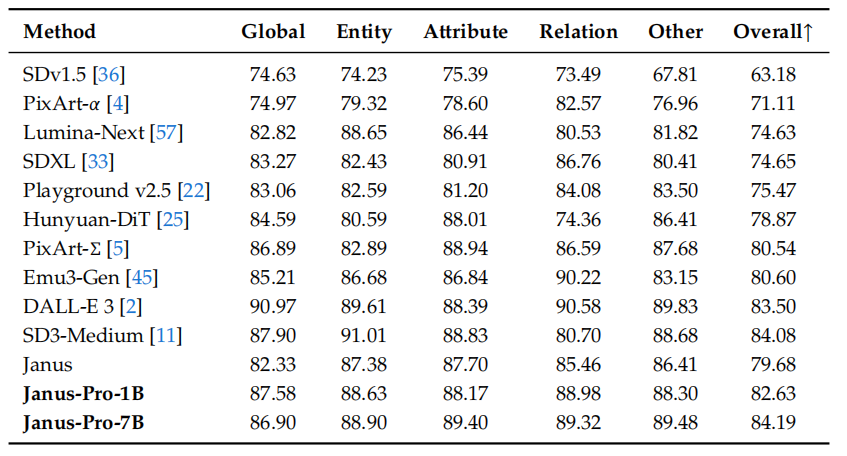
多模态理解性能:表3展示Janus-Pro与最先进的统一多模态模型和仅用于理解的模型的实验结果,其中“Und.”和“Gen.”分别表示“理解”和“生成”,使用外部预训练扩散模型的模型用“†”标记。Janus-Pro在整体上取得了最佳结果。这一优势可以归因于其为多模态理解和生成任务解耦了视觉编码,从而缓解了这两项任务之间的冲突。即使与其他规模显著更大的模型相比,Janus-Pro仍然具有很强的竞争力。例如,在所有基准测试中,Janus-Pro-7B在GQA之外的所有任务上均优于TokenFlow-XL(13B)。
表 3 在多模态理解基准测试中与最新技术的比较
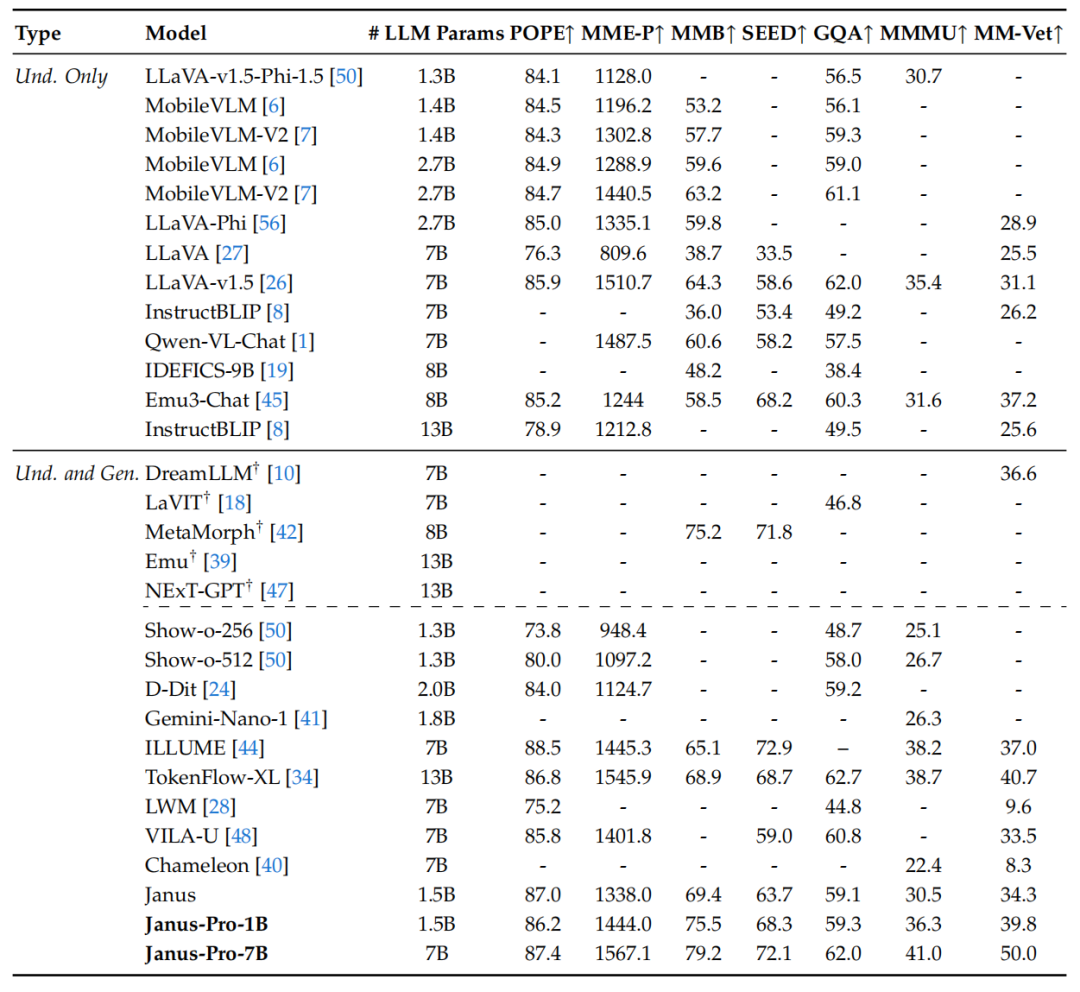
视觉生成性能:表4展示了不同模型在基准测试GenEval上的评估。Janus-Pro-7B在GenEval上获得了80%的总体准确率,超越了所有其他统一多模态或仅用于生成的方法,例如Transfusion(63%)、SD3-Medium(74%)和DALL-E 3(67%),表明Janus-Pro在指令遵循方面具有更强的能力。
表5展示了不同模型在基准测试DPG-Bench上的评估。注意,除了Janus和Janus-Pro,该表中的方法均为专门用于生成的模型。具体而言,Janus-Pro在获得了84.19分,超过了所有其他方法。这表明Janus-Pro在遵循详细指令进行文本到图像生成方面表现出色。
表 4 不同模型在基准测试GenEval上对文本到图像的生成能力
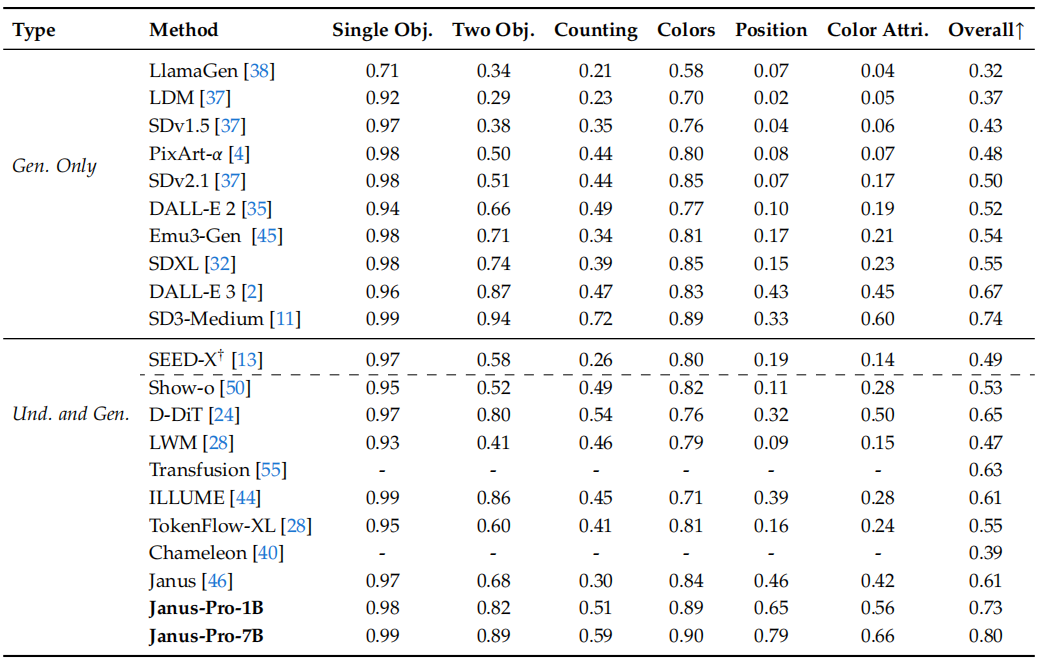
表 5 不同模型在基准测试DPG-Bench上对文本到图像的生成能力
4
定性结果
图4展示了多模态理解的可视化结果,其中所用模型为Janus-Pro-7B,视觉生成的图像输出分辨率为384×384。Janus-Pro在处理来自不同背景的输入时表现出令人印象深刻的理解能力,展现了其强大的功能。图4的下半部分展示了一些文本到图像生成的结果。Janus-Pro-7B生成的图像非常逼真,尽管分辨率仅为384×384,但仍然包含许多细节。对于富有想象力和创造力的场景,Janus-Pro-7B能够准确捕捉提示中的语义信息,生成合理且连贯的图像。

图 4 多模态理解和视觉生成能力的定性结果
结论
本文从训练策略、数据规模和模型规模三个方面介绍了对Janus进行的改进。这些改进使得Janus-Pro在多模态理解和文本到图像指令遵循能力方面取得了显著进步。然而,Janus-Pro仍然存在一些局限性。在多模态理解方面,输入分辨率限制为384×384会影响其在OCR等细粒度任务中的表现。对于文本到图像生成,低分辨率与视觉分词器引入的重建损失相结合,导致生成的图像虽然语义丰富,但仍然缺乏细节。例如,占据有限图像空间的小面积面部区域可能会显得细节不足。提高图像分辨率可以缓解这些问题。
煤炭领域的应用潜力
1
可应用场景
结合煤矿智能化需求,Janus-Pro可在以下场景发挥价值:
安全监测与灾害预测
多模态数据分析:融合井下摄像头(可见光/红外)、传感器(瓦斯浓度、振动)数据,通过Janus-Pro的理解能力实时识别顶板裂缝、瓦斯泄漏等隐患。
灾害模拟生成:利用Janus-Pro的生成能力合成事故场景(如火灾扩散模拟),辅助应急预案制定。
设备智能运维
故障诊断:解析设备运行日志、振动信号与图像(如皮带磨损),生成维修建议。
知识库构建:自动生成设备维护手册的图文说明,降低培训门槛。
井下作业自动化
机器人指令控制:将自然语言指令(如“清理A3区域积水”)转换为机器人可执行的路径规划与动作序列。
低光照图像增强:通过生成模块修复模糊或高噪声的监控图像,提升识别准确率。
2
未来的挑战与优化方向
数据适配:需针对煤矿场景(如粉尘、低光照)微调模型,增加矿用设备、地质结构的专属数据集。
实时性优化:7B模型可能需要轻量化部署(如模型蒸馏)以满足井下边缘计算的低延迟需求。
Janus-Pro通过解耦式架构设计、数据-模型双扩展策略,为多模态任务提供了高效统一的解决方案。其在煤矿领域的应用前景广阔,尤其在安全监测、设备运维等场景中,有望推动矿山智能化向“感知-决策-执行”全链条自动化迈进。未来可进一步探索模型在跨模态时序数据分析(如矿压预测)中的潜力,并结合领域知识进行垂直优化。
声明
本文内容为论文学习收获分享,受限于编者知识能力,对原文的理解可能存在偏差,最终内容请以原论文为准。本文信息旨在传播和交流,不代表本号观点。文中内容如涉及版权问题,请及时与我们联系,我们将在第一时间回复并处理。

矿山人工智能研究院
电 话:010-84263758
E-mail:solstone-support@mail.ccri.ccteg.cn
地 址:北京市朝阳区青年沟路5号
供稿 | 李凯
编辑 | 丁国原
校审 | 杨凌凯



